Data Science in Production
March 1, 2019
Most people working in the data science field would agree that it is not the newest technologies or the best model that we should pursue. Unlike in academic settings, what we always pursue in the real world is whatever best solves the business problem. With this being said, a well-performing machine learning model, which runs in the local Python environment and only generates CSV files cannot be considered a solution most of the times. Thus to turn such a raw model into a “solution”, a deployment process is needed. So if we want to put a data science project into production, what are the people involved in the process and what is the role should a Data Scientist play?
Data science is a large and continually expanding field, so is the job titled “Data Scientist”. Thus let’s first give it narrower definition and then discuss how could the deployment process work. Nowadays a Data Scientist can be doing many things, ranging from writing SQL queries to designing deep learning frameworks. To category this, this is how I define the two categories of data science projects.
The first category: Data Storytelling, which means that Data Scientists write a consulting-level report with Excel spreadsheet and static visualization to provide KIPs for business people’s decision making, or design interactive dashboards so that business people can play around with it, monitoring live data, and making decisions. This type falls into the first category of analytics, which is explanatory analytics. The deployment of the first category is relatively simpler since a slide deck or a dashboard is already a product that can be used by the end user. Moreover, with newly developed APIs, data visualization tools such as Tableau allow connection with Python and R, meaning that machine learning models can be easily integrated with a dashboard. For example, a time series model that predicts the future trend of time series data, or a classification model that red-labels churning customers for the sales manager. The whole process from connecting with the data source to generating the result (solution) could be finished solely by a skilled Data Scientist, and the most important part of the first category would be understanding the business context and knowing what the decision makers want.
The second category I call it Data Modeling, which leans more towards predictive and prescriptive analytics. It is through putting machine learning or optimization models into production that at one point the machine itself can make decisions on a large dataset or make real-time predictions. The second category, of course, is more trending but also requires more effort to be put into production. The final product should be embedded into the back end and even the front end of the company’s IT infrastructure. First, let’s assume in a fully mature technology company, there would be clear roles and responsibilities involved in the deployment process of a machine learning project. Start with Data Engineers who set up the big data infrastructure and data sourcing pipeline. And then Data Scientists do feature engineering and analyze which machine learning approach to use. Next, they model the algorithm and test the algorithm in the test set. Data Scientists’ task is normally done on a static dataset. Finally, Machine Learning Engineers come into the process. They leverage big data tools and programming frameworks to ensure that the raw data gathered from data pipelines are ready to flow into the model. And then take the prototyped model from Data Scientist and write production-level code to make it work in a production environment, with high volume and large scale. It could be built into the back end so that the server is making real-time decisions based on it, like a recommender system deciding which product to be present to the customer. Or it could be further pipelined into the front end so that customer can see the exact product picture on his/her mobile app.
Data Engineer vs. Data Scientist vs. Machine Learning Engineer: The three roles, as mentioned above, are normal settings in a mature technology company. However, the majority of the companies nowadays just started hiring their Data Scientists, leaving the other two positions held by people from the former organization. Data Engineer’s work is expected to be done by traditional Database Administrators, who might only familiar with traditional databases, meaning that they would have trouble building real-time data pipelines such as Kafka, which is essential for streaming apps. Machine Learning Engineer’s task, on the other hand, is normally expected to be done by the traditional IT team of the company, which consists of developers don’t understand machine learning and databases.
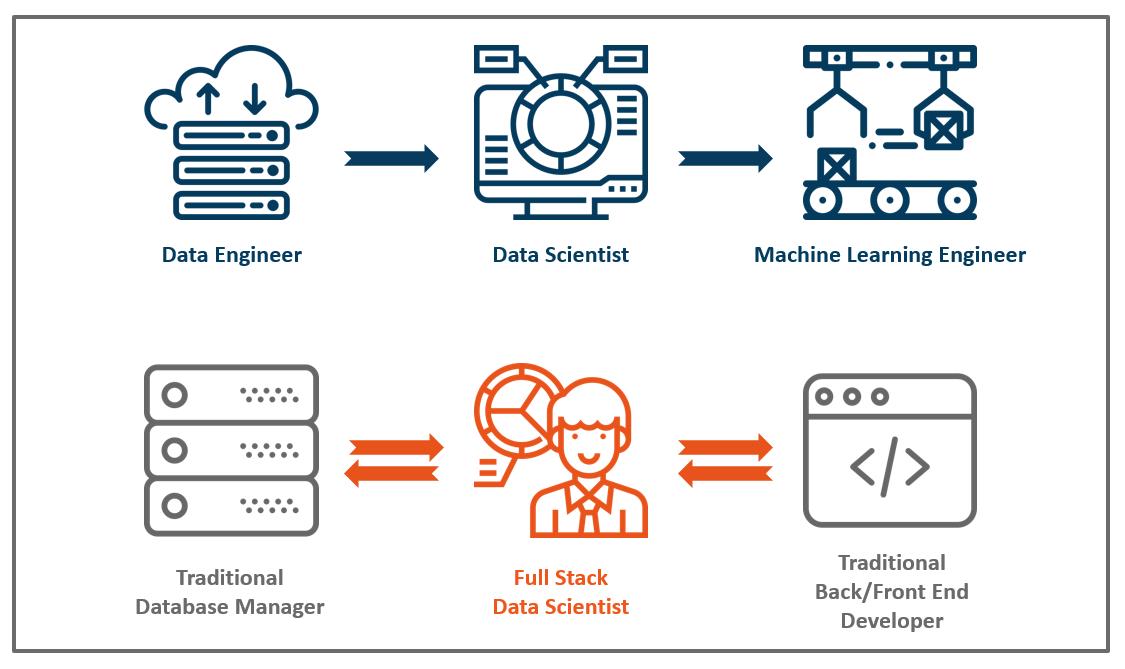 Full Stack Data Scientists Faciliate The Two-way Communication
Full Stack Data Scientists Faciliate The Two-way Communication
Thus when it comes to a company who just started implementing data science strategy, the deployment process is normally inefficient or even stuck. Also with months of developing time, the original model trained by Data Scientists might be already outdated. Thus if a Data Scientist not only has a solid statistical and modeling background (a Statistics degree), but is familiar with database technologies and software developing (a Computer Science degree), he/she would be extremely valuable for putting the second category of data science project into production. The person who is able to facilitate and accelerate the whole process and deliver end-to-end solutions is named “Full Stack Data Scientist”. As striving Data Scientists, we should always try to widen our abilities and strengthen our skills in areas beyond the traditional statistical modeling and ML areas, in order to be fully functional in companies. I hope “Business Full Stack Data Scientist” will be my next stop.